
Seven Ways to Stop Your AI From Making Things Up
AI hallucinations cost businesses real money. Hallucination rates have dropped from 38% to 8%, but you can push that lower with these practical techniques.
Why do AI models hallucinate?
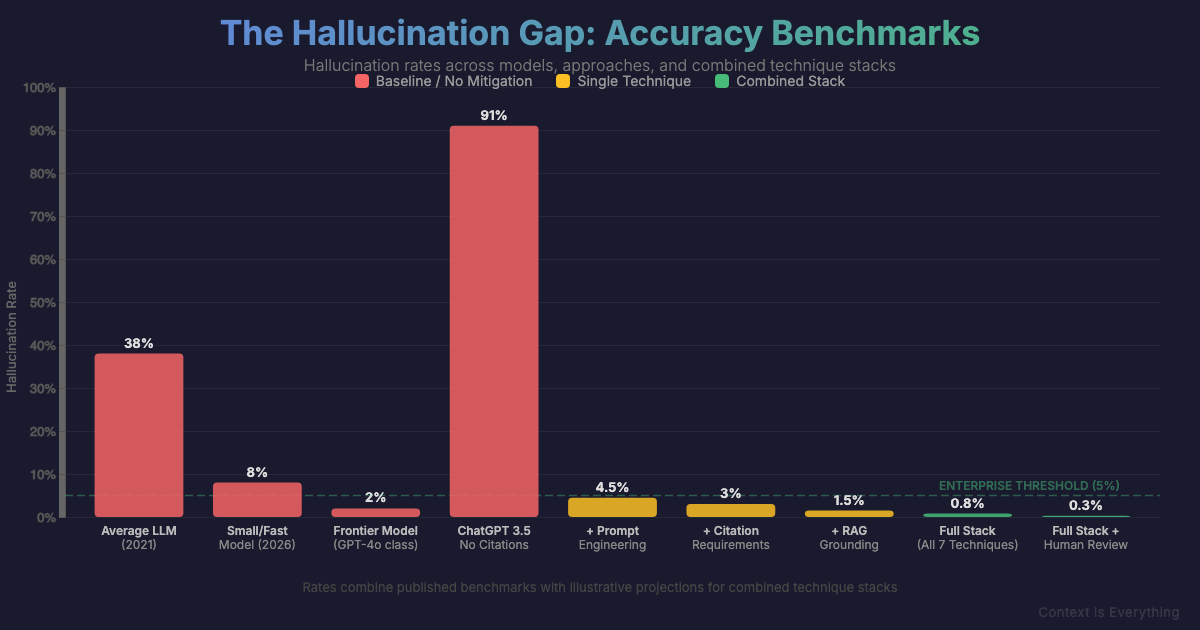
AI hallucinations cost businesses real money. When your chatbot invents a refund policy that doesn't exist or your research tool fabricates citations, you're not just dealing with embarrassment—you're facing potential legal liability. The good news: hallucination rates have dropped from 38% in 2021 to around 8% today. The better news: you can push that number even lower with the right approach.
How can you reduce AI hallucination rates?
1. Choose the Right Model (Speed Isn't Everything)
Groq's CEO Jonathan Ross put it bluntly: "A lot of people get really excited, but then they actually verify what they got and you realise that you got a lot of junk." Frontier models like GPT-4o achieve 1-2% hallucination rates; smaller, faster models run 3-8%+. For customer-facing applications, the speed savings rarely justify the accuracy trade-off.
2. Add Emotional Stakes to Your Prompts
This sounds absurd, but Microsoft researchers proved it works. Adding phrases like "This is very important to my career" improved accuracy by 8% on average—and up to 115% in some cases. Human evaluators rated these responses 10.9% higher on truthfulness. LLMs trained on human data respond to stakes and consequences.
3. Be Explicit About Constraints
Tell the model exactly what to do when it doesn't know something: "Only use information from the provided context. If you cannot find the answer, say 'I don't have enough information.'" Put this in your system prompt AND your output format instructions—multi-location instructions improve compliance.
4. Force Citations (Then Verify Them)
Without citation requirements, ChatGPT 3.5 hallucinated 91%+ of its references. Tools with built-in citation requirements showed near-zero hallucination rates. Require sources for every claim—but verify them, because some models fabricate convincing-looking URLs. Chain-of-Verification techniques increase factual accuracy by 28%.
5. Make It Show Its Work
"Let's think through this step by step" isn't just a prompt trick—Google's research shows Chain-of-Thought prompting improves reasoning accuracy by over 30%. When models must show intermediate steps, errors become visible and correctable. They can't jump to plausible-sounding conclusions without justification.
6. Ground It in Your Data (RAG)
Retrieval-Augmented Generation—pulling relevant documents before generating responses—reduces hallucinations by 60-80%. You're changing the task from "recall from your training" to "answer from these specific facts." The model becomes a synthesiser rather than a guesser.
7. Build Verification Into Your Pipeline
Since LLMs will hallucinate, build defences: check that cited URLs return 200 OK, verify named entities exist, cross-check facts against multiple sources. As Parasoft's engineers put it: "You need to actually have code double-check the answer." Treat hallucination prevention as a systems problem, not a prompting problem.
The bottom line: No single technique eliminates hallucinations. Stack these approaches—better models, smarter prompts, grounded retrieval, and automated verification—and you'll get outputs you can actually trust. Our AI accuracy checklist can help you assess where your setup stands. If the prompts themselves are the weak link, Briefing in Contours walks you through three staged prompts so the model has the context before it has the question.
---
Sources
Related Articles
Why Most AI Projects Fail (And What the 5% Do Differently)
MIT's Project NANDA found 95% of enterprise AI pilots deliver zero return. Companies have invested £30-40 billion with nothing to show. But 5% achieve rapid revenue acceleration. The difference isn't the technology - it's implementation and context.
Where to Start with AI: The First Steps Every Business Should Take
You've decided AI makes sense. Now what? Three foundational questions help you prepare for productive conversations about AI implementation: what specific problem you're solving, whether context matters in your situation, and how you'll measure success.
8 AI Mistakes Costing UK Small Businesses £50K+ (And How to Avoid Them)
AI spending is up six-fold, yet UK small business adoption crashed from 42% to 28%. Discover the 8 expensive mistakes costing £5K-£50K+ each to fix—and learn how businesses getting it right avoided these patterns.